
臨床研究・疫学研究のための因果推論レクチャー
[第7回] 時間とともに変化する曝露を扱う
連載 井上 浩輔,杉山 雄大,後藤 温
2021.10.04 週刊医学界新聞(通常号):第3439号より
シェアする
Today's Key Points
✓ 曝露状況が時間とともに変化する場合は交絡因子が曝露のタイミングにより異なり,注意が必要である。
✓ 時間とともに変化する曝露を扱う際には,治療確率による逆確率重み付け(Inverse Probability of Treatment Weighting:IPTW)やG-computationの手法が有用である。
✓ IPTWとG-computationはそれぞれ,曝露,アウトカムに対するモデルの正しい設定が重要になる。
前回までは,研究開始時の曝露状況が追跡期間中に変わらないシンプルなシナリオを扱ってきました。しかし実際の研究では,曝露状況が時間とともに変化するケースに出会うことがしばしばあります。例えばコホート研究において,研究開始時にスタチンを内服していた人が,その後のフォローアップで内服を中断していた場合などです。今回は,スタチンを内服継続する場合の3年後の冠動脈疾患発症リスクが,全く内服しない場合のリスクと比べてどの程度下がるか,という経時的な情報を含む臨床の疑問に答えるための手法を紹介します1~3)。
曝露が時間とともに変化することで生じる問題点
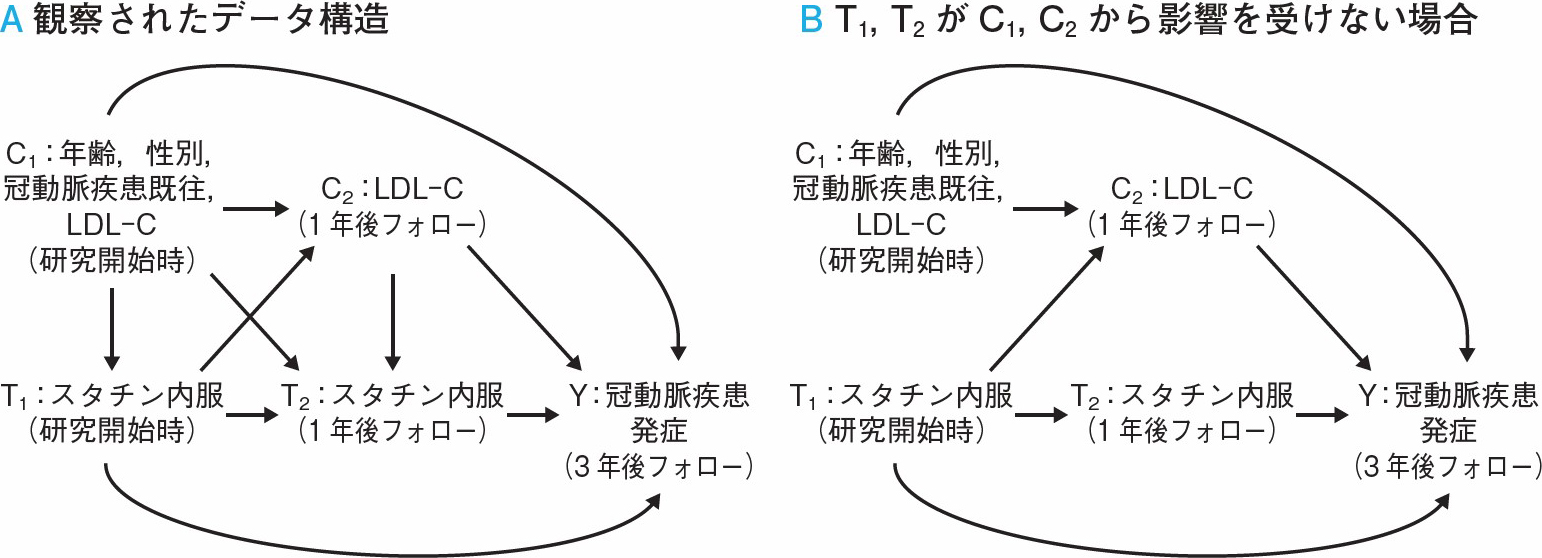
そもそもなぜ,曝露状況が変化する際に特別な注意を払う必要があるのでしょうか? この問いに答えるために前回までの連載内容から,調整すべき交絡因子について図1-Aの例で考えてみましょう。コホート研究開始時のスタチン内服(T1)による冠動脈疾患発症(Y)への因果効果を推定するには,研究開始時の年齢,性別,冠動脈疾患既往,LDLコレステロール値(LDL-C,C1)を調整することで,バックドア経路(T1←C1→Y)を閉じる必要がありました。ここで,1年後フォローのLDL-C(C2)は中間因子であるため調整することは望ましくありません(第3回参照)。一方で,1年後フォローのスタチン内服(T2)によるYへの因果効果を求める際には,バックドア経路(T2←T1→Y,T2←C2→Y)を閉じるために,C1の他にT1,C2でも調整しないとバイアスが生じます。以上から,研究開始時・フォロー時共にスタチン内服していない参加者(T1=T2=0)と比較して,両時期にスタチン内服している参加者(T1=T2=1)の冠動脈疾患発症リスクがどの程度下がるかを,T1,T2,T1×T2を含んだ一般的な回帰モデルで検討するのは困難です。
治療確率による逆確率重み付け(IPTW)
そこでまず,IPTWのアプローチを紹介します(図2-A)。図1-Aで難しかった点は,T1にとって中間因子であるC2が,T2にとっては調整すべき交絡因子であることでした。一方で...
この記事はログインすると全文を読むことができます。
医学書院IDをお持ちでない方は医学書院IDを取得(無料)ください。
いま話題の記事
-
どう届ける? いかに選ばれる?
with AI 医療コミュニケーション対談・座談会 2026.07.14
-
ピットフォールにハマらないER診療の勘どころ
[第22回] 高カリウム血症を制するための4つのMission連載 2024.03.11
-
サルコペニアの予防・早期介入をめざして
AWGS2025が示す新基準と現場での実践アプローチ寄稿 2026.03.10
-
ピットフォールにハマらないER診療の勘どころ
[第3回] シリンジ1つで頻脈対応 魔法のようなPSVTマネジメント連載 2022.08.08
-
医学界新聞プラス
[第6回]★3という沈黙――人間の感情は中間的であるほど表現しにくい
★1の向こう側連載 2026.07.27
最新の記事
-
どう届ける? いかに選ばれる?
with AI 医療コミュニケーション対談・座談会 2026.07.14
-
対談・座談会 2026.07.14
-
EBPを生きた実践にする
基礎教育からDNPまで,求められる学びと役割対談・座談会 2026.07.14
-
インタビュー 2026.07.14
-
藤澤雄太氏に聞く
患者と信頼関係を築く動機づけ面接
説得ではなく伴走で変化を促すインタビュー 2026.07.14
開く
医学書院IDの登録設定により、
更新通知をメールで受け取れます。