
日本のゲノム医療(中川英刀,高坂新一,徳永勝士,小崎健次郎)
対談・座談会
2018.01.01
シェアする
【座談会】日本のゲノム医療構築の基盤はデータベースと人材育成 | |
|
| |
|
近年,ゲノム医療実現の動きが世界中で急速に進んでいる。日本でも臨床応用に向けた研究が盛んに行われ,がんや難病・遺伝性疾患など一部の治療薬や検査はすでに保険承認されている。その一方で,欧米に比べると日本ではゲノム医療の体制構築が遅れてきた。日本におけるゲノム医療をさらに推進させるにはどうすればよいのか。本座談会では,データベース整備と人材育成に焦点を当て,現状と今後の展望が議論された。
中川 がんや難病など一部の疾患でゲノム情報に基づく個別化医療(ゲノム医療)が実現しつつある一方,日本のゲノム医療の体制構築は始まったばかりです。そこで今日は,医学と医療双方の発展に欠かせないインフラであるデータベース(以下,DB)と人材に焦点を当て,日本における現状と課題を議論したいと思います。
最初に髙坂先生,日本のDB整備の現状をお話しください。
髙坂 日本版ClinVarといえる「臨床ゲノム情報統合データベース(MGeND;Medical Genomics Japan Database)」が2018年から非制限公開される予定です。AMEDによる整備事業は2016年に開始されました。ヒトゲノムの多様性と関連する疾患の情報を統合・解析するDBとして,研究者のみならず,臨床の医療従事者にも広く活用してもらうことをめざします。
中川 なぜそのようなDBを整備することになったのでしょうか。
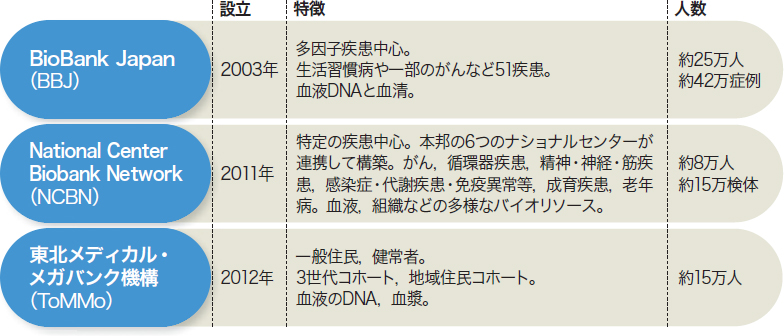
髙坂 日本にはもともと優れたバイオバンク(表)があり,ゲノム研究でもそれぞれ独自の研究成果を出してきました。しかし,ゲノム医療などへの二次利用はあまりされてきませんでした。また,公的資金を用いた研究で多数のゲノム解析が行われるものの集約されておらず,研究代表者が替わればデータは霧散してしまっていました。
| 表 日本の3大バイオバンク(クリックで拡大) |
| バイオバンクも,バイオバンク情報横断検索システムにおいて容易に試料を探索できるよう可視化され,国内で広く共有されるようになる。 |
|
中川 一定規模のDBが一時的にできることはあっても,永続するものではなかったのですね。
髙坂 2015年に発足した「ゲノム医療実現推進協議会」で議論となり,AMEDが所管するゲノム研究はデータシェアリングポリシーにのっとりDBに登録し,制限公開または非制限公開することになりました。これをさらに発展させ,疾患横断的なDBを構築していきます(図1)。
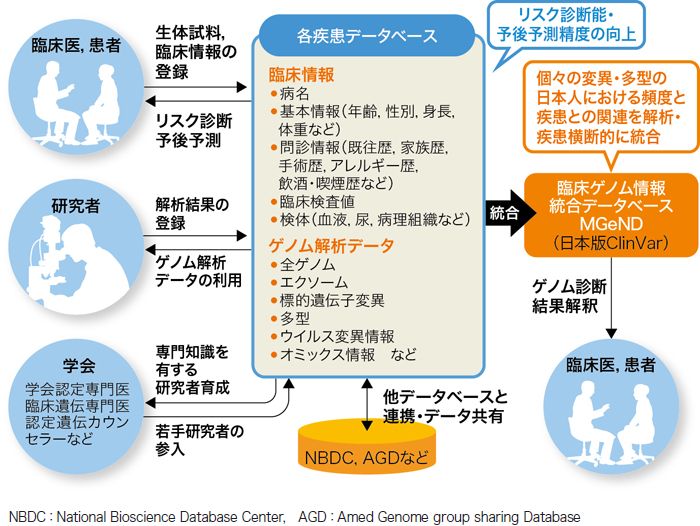
|
| 図1 各疾患データベースから疾患横断的なデータベースへ(クリックで拡大) |
| 各疾患において,臨床情報や生体試料,ゲノム解析データを蓄積するデータベースの構築が進んでいる。 臨床情報やゲノム情報が蓄積するほどリスク診断能・予後予測精度は向上していき,データベースが一層利活用されるようになると期待される。そして,それらのデータを統合し,個々の変異・多型の日本人における頻度と疾患との関連を示した疾患横断的なデータベース「臨床ゲノム情報統合データベース(MGeND)」(日本版ClinVar)の整備が進められている。 |
臨床で役立つデータベースに必要なのは?
[患者ゲノム情報]+[健常者ゲノム情報]
中川 小﨑先生はIRUDで,DBを活用したゲノム医療に取り組んでいます。
小﨑 難病の臨床現場では,エクソーム解析や全ゲノム解析による診断がここ5年ほどで劇的に進んでいます。多くの医師が何年かけても診断できなかった未診断疾患の約3割に診断が付いています。
中川 診断が付くようになった要因は何でしょうか。
小﨑 未診断疾患の多くは頻度が低い疾患です。たとえ既知の疾患であっても十分な症例経験を積むのが難しく,診断は困難でした。その問題が疾患データの共有とゲノム解析によって解決されたのです。
中川 どのように診断するのですか。
小﨑 遺伝子変異が原因と思われる患者に対して,疾患原因遺伝子を特定しない網羅的ゲノム解析をします。そして健常者データを「引き算」します。ToMMoによって大量の日本人健常者データが得られるようになり,ゲノム医療が大きく進みました。
中川 健常者データも用いるのですね。
小﨑 疾患の原因変異を探索するためには,病的変異のデータだけでなく,どの範囲の変化であれば「健常」かのデータが必要です。
ヒトゲノム計画が始まった当初は,ヒト標準塩基配列が一度わかれば,その後は患者のゲノムを全部調べれば疾患の原因が何でも解明できるようになるという楽観的な見方もありました。しかし実際には単一遺伝子疾患でもそう簡単ではありません。ヒト標準塩基配列は,数人の遺伝子を組み合わせて作られたいわばモンタージュ写真です。健常者でも,全ゲノムの1~1.5%にすぎないエクソンに3万箇所以上のvariant(ヒト標準塩基配列との差)が見つかっています。
中川 健常のパターンはヒト標準塩基配列以外にもたくさんあるということですね。
小﨑 病的変異にも健常な変異と同様に幅があります。同じタンパク質をコードする遺伝子でも機能に与える影響が比較的少ない部分が変異している症例が,診断基準の全ては満たさない非典型例の中にあるというデータが蓄積されてきています。今後,患者ゲノム,健常者ゲノム両方のデータ蓄積を一層進めていく必要があります。
中川 米国ではすでに10万を超える病的variantデータが蓄積され,Clin Var DBとして世界に向けて非制限公開されています。世界規模のDBがある中,日本独自のDBを作る必要があるのでしょうか。
小﨑 海外DBの多くは欧米人の情報をもとにしており日本人はほとんど含まれていません。日本と欧米では明らかに遺伝的特徴が異なります。アジア系の中でも差は大きいです。疾患遺伝子の同定などでは国際的な情報共有が重要ですが,日本の臨床現場で活用するには日本独自のDB構築が必須です。
非典型例や多因子疾患解明に必要なのは?
[臨床情報]+[ゲノム情報]
中川 徳永先生は日本人類遺伝学会で,さまざまな疾患関連のvariantや免疫に重要なHLA型の情報を以前から収集してきました。
徳永 疾患を遺伝学的見地から大きく分けると,単一遺伝子疾患と多因子疾患,そしてがんに代表される体細胞遺伝子variantによる疾患です。求められるゲノム情報,臨床情報の特徴はそれぞれ異なります。DBに収載される情報も,疾患ごとに違う性質のものを用意する必要があります。ゲノム情報については,がんなら主に腫瘍組織における体細胞遺伝子のvariant情報,単一遺伝子疾患では発症の原因となる疾患variant情報,多因子疾患では発症に関連する多数のリスクvariant情報が必要です。
中川 がんではドライバー遺伝子や治療標的遺伝子が次々に発見され,診断と特異的な薬剤の開発・選択が急速に進んでいます。多遺伝子パネル検査による包括的診断も可能です。また,先ほど小﨑先生から紹介があった難病を含む単一遺伝子疾患では変異の臨床的な意義がどんどん明らかになっています。しかし,それ以外の疾患はどうでしょうか。多因子疾患では,さまざまなvariantが見つかる一方,解釈しきれないこともまだ多い印象です。
徳永 発症予測には至らないものの,リスクを上げる要因は見つかってきています。例えば感染症は,感染の機会という環境要因が最大のリスク因子ですが,宿主であるヒトの遺伝的変異と病原体の変異の組み合わせでもリスクが変わることがわかってきています。
中川 環境要因を組み合わせた解析により,発症予測,予防に関する研究が進む可能性がありますね。
徳永 また,これまで多因子疾患解析は網羅的なゲノム変異解析から表現型にかかわる遺伝子変異を探していくGWASが主体でしたが,網羅的な表現型解析から関連する遺伝子変異を特定していくフェノムワイド関連研究(PheWAS)も行われるようになっています。表現型,つまり臨床症状を広範かつ詳細に集め,特定のゲノム変異との関連を検出する解析法です。
小﨑 ゲノム研究は長年,gene huntingアプローチが一般的でした。病名が判明している状況で,症状が均一な患者を集め,共通の遺伝子変異を見つける方法です。しかし医療現場では,一般的な傾向や診断基準から外れる患者や,いくつかの要素を複合的に持つ患者もいます。
今後は非典型症状を含めた幅広い情報を蓄積していくべきだと思います。典型例から外れるものの中にこそ新しい発見があるかもしれません。
中川 そうした点からも,ゲノム情報と臨床情報の両方が重要なのですね。
しかしデータの収集・活用に当たっては,個人情報の取り扱いが気になります。2017年に施行された改正個人情報保護法では,ゲノムデータが個人識別符号に位置付けられ,病歴や検査結果なども要配慮個人情報とされました。徳永先生は改正の委員を務められましたね。
徳永 はい。個人情報保護法の改正に伴い,研究倫理指針も改正されました。誤解されることもあるのですが,研究として扱う場合は個人情報保護法の適用除外とされ...
この記事はログインすると全文を読むことができます。
医学書院IDをお持ちでない方は医学書院IDを取得(無料)ください。
いま話題の記事
-
ピットフォールにハマらないER診療の勘どころ
[第22回] 高カリウム血症を制するための4つのMission連載 2024.03.11
-
VExUS:輸液耐性が注目される今だからこそ一歩先のPOCUSを
寄稿 2025.05.13
-
サルコペニアの予防・早期介入をめざして
AWGS2025が示す新基準と現場での実践アプローチ寄稿 2026.03.10
-
ピットフォールにハマらないER診療の勘どころ
[第11回] めまい診療をTiming and Triggerでスッキリ整理! Dangerous diagnosisを見逃すな①連載 2023.04.10
-
寄稿 2022.04.11
最新の記事
-
対談・座談会 2026.06.09
-
対談・座談会 2026.06.09
-
対談・座談会 2026.06.09
-
全学部の新入生3000人が学ぶ命の守り方
京大・救命救急講習12年の歩み取材記事 2026.06.09
-
寄稿 2026.06.09
開く
医学書院IDの登録設定により、
更新通知をメールで受け取れます。