
連載 Evidence-Based Medicineのための
実践統計学入門
山本和利 京都大学医学部附属病院総合診療部講師
(3) 推定
●事例一般住民の血清Na平均値は140mEq/lで正規分布に従い,標準偏差SD(σ)は2.5mEq/lである(標準偏差については第2224号第1回参照)。患者25人を抽出し血清Naを測定したところ,その平均値は138mEq/lであった1)。この差は統計的に有意であろうか?
●母集団と標本
実際に全体のデータを集めると,膨大な量になってしまい,必要な情報を得ることが難しい。そこで,ある集団について知りたいとき,全体でなく部分から推測することができる。
無作為に選ぶことによって部分が全体の縮図となる(標本抽出)。無作為に抽出することにより偏りがなく,独立したデータが得られる。健康者に偏りやすいボランティアや数パーセントしか返答がないアンケートを標本にするとバイアスが生ずる。知りたいと思う集団全体を母集団と呼び,母集団からその一部を選び出し,分析して,母集団についての推測を行なうことを統計的推測と呼ぶ。
●正規分布
ここで分布について考えてみたい。ある標本データを得るとき,nが大きい(n>30)ときには,その平均はほぼ正規分布に従う(中心極限定理)。nが大きければ,ヒストグラムを描いたとき,極端に左右に歪んでいない限り正規分布としてデータ処理できる。そのとき平均μ,分散σ2の正規分布をN(μ, σ2)と表す。
●標準正規分布
μ=0,σ=1の正規分布を特に標準正規分布と呼び,N(0,1)と表せる。標準正規分布であればμからどれだけの標準偏差(σ)離れているか知ることができる。
ある値XのスコアはZ=(X-μ)/σで表される。すなわち,μとσがわかれば,ある与えられた値Xが分布のどこに位置するかを知ることができる。例えば,うつ病を診察するときに用いるあるスコアのμが52.1点,σが10.5点なら,そのスコアが68点の患者はZ=(68-52.1)/10.5=1.51となり,1.51σだけ平均から離れたところに位置することがわかる1)。1σ以内には68.2%,2σ以内には95%が含まれる(図1)。
このことは抽出した分布にも同様に当てはまる。事例にも当てはめてみよう(標本の場合には,母集団と異なり,分母にはSE=SD/√n=2.5/√25を用いる)。
標本の平均値138mEq/lをZ=(X-μ)/SEの式に代入して,(138-140)/0.5=-4.0となる。すなわち,母集団の平均から-4SE離れていることがわかる。
{kind=link}

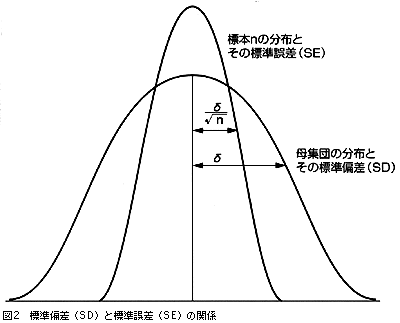
●標準偏差と標準誤差
標準偏差(SD)と標準誤差(SE)はよく誤解され,混同して用いられるのは初心者に限らないようだ。例えば,SDとSEの区別ができるかどうかを知るために2つの多枝選択問題をデンマークの医師たちに解かせたところ,2問とも正解したのはたったの6%であった2)。また,SDとSEの取り扱いを間違えたままNew England Journal of Medicineを含む有名雑誌に掲載された20の論文を取り上げ,槍玉にあげている例もある2)。
SDとSEはまったく別のもので,SEは標本データからその母集団の平均の散らばり具合を推定するために用いられる。例えば,ある母集団からn人を抽出し血清Naを測定する。それをn人ずつのグループで繰り返す。この場合,各グループの平均値の散らばりをSEと呼び,SE=SD/√nという関係で表される(図2)。
事例で考えてみよう。母集団となる病院全体の患者のSDは2.5なので,住民から25人抽出したときのSEを求めると,SE=SD/√nの式より,2.5/√25=2.5/5=0.5となる。
{kind=link}
●信頼区間の推定
1つの標本から母集団はどのようなものかを推測した結果を表すのに,点推定と区間推定とがある。点推定は平均値や比率を1点表示するやり方であるが,医学論文では点推定より区間推定が用いられる。
区間推定とは,母集団の平均(μ)や分散(σ2)を,適当な幅を持たせて標本の値から推定しようというものである。推定の精度を100(1-α)%のようにパーセントで表す。(1-α)を信頼係数と呼び,区間(L,U)を100(1-α)%信頼区間と呼ぶ。
信頼区間の意味は,くり返し異なった標本で計算した場合,母集団の真の値を区間内に含むものの割合が(1-α)ということである。通常95%(α=0.05)に設定されることが多い。
信頼区間の幅(U―L)はαを一定にした場合,標本の大きさnが大きくなるに従って小さくなり,通常1/√nのオーダーで0に近づく。幅が小さいほど推定は正確である。
正規分布する母集団の平均μを区間推定するやり方を具体的に示そう。母集団のσ2がわかっている場合と,わかっていない場合で方法が異なる。
一般に母集団からn人を抽出したときの母集団のμの95%信頼区間はx-1.96×σ/√n≦μ≦x+1.96×σ/√nである。事例では母集団のσがわかっているので,この式を用いて区間推定ができる。25人抽出したとき,95%信頼区間は140-1.96×σ/√n~140+1.96×σ/√nであるから,140±0.98で139.02~140.98mEq/lとなる。
母集団の95%信頼区間と患者25人の平均値138mEq/lを比較してみよう。
138mEq/lはこの95%信頼区間に入らないので,統計的には有意な差であると考えられる。多くの場合には母集団のσ2がわかっていないことが多い。そこで,母集団のσ2の代わりに標本の分散(s2)を用いる。σ2とs2との間にはσ2=s2×n/(n-1)という関係が成り立つが,σがわからないので生データから計算することになる。
標本の分散s2を求めるときにはnではなくn-1で割る。仮に4人の患者の値が135,136,140,141とすると平均値は138なのでs=√{(135-138)2+(136-138)2+(140-138)2+(141-138)2}/(4-1)=2.94と計算できる。前述の式のσをsに置き換えると,母集団のμの95%信頼区間はx-1.96×s/√n≦μp≦x+1.96×s/√nとなる。ただし,1.96という数字はα=0.5でnが120を越えるような場合を想定して正規分布表から得られたものである。標本数nが小さい場合には使えない。そのときにはt分布表の(n-1)のα=0.05に当たる数字に置き換える必要がある。ここではt分布表の(4-1)のα=0.05に当たる数字2.353を使う必要がある。
4人の患者集団のμpの95%信頼区間は138-2.353×2.94/√4≦μp≦138+2.353×2.94/√4と計算でき,134.54~141.46mEq/lとなる。
●統計的有意差と臨床上の重要性
統計的有意差があるからといって臨床上重要であるかどうかは別問題である。これまでみてきたように,統計的有意差はnを大きくすることによって可能になる。事例で血清Na値2mEq/lの差が統計学的には有意であっても,臨床上,その差が重要であるとは思われない。
●ここまでわかるとどの程度,論文が読めるか?
New England Journal of Medicineなどの標本から推定した医学論文を批判的に読むことができる。
●まとめ
■標準偏差と標準誤差を混同してはならない。
■標本nの標準誤差=標準偏差/√nという関係になる。
■母分散σ2と標本分散s2との間にはσ2=s2×n/(n-1)という関係が成り立つ。
■統計的有意差と臨床上の重要性とは別の問題である。
参考文献