
連載 Evidence-Based Medicineのための
実践統計学入門
山本和利 京都大学医学部附属病院総合診療部講師
(4) 仮説検定・t検定
●事例1
50人の高血圧患者を抽出し,降圧剤Aによる無作為対照試験の同意を得て,25人ずつの2群に分け経過を観察した。その結果は両群ともベル型に分布し,治療群は平均血圧の平均値:98mmHg,標準偏差(SD):6mmHg,コントロール群は平均血圧の平均値:102mmHg,SD:8mmHgであった。「治療群とコントロール群の4mmHgの差は偶然で説明できるだろうか?」
●帰無仮説
ある群とある群に違いがあることが期待されるとき,「差がない」という帰無仮説を立てる。帰無仮説が否定されれば,差があることになる。このとき採用するものを対立仮説と呼ぶ。2群に差がないとの仮定(帰無仮説H0:μ=μ0)のもとで測定したデータから得られた確率(P)を,正規(Z)分布やt分布などを用いて検定量Z値やt値から求める。
あらかじめ決めておいた有意水準α(通常5%または1%)とp値を比較し,p値がαより小さければ小さいほど,めったに起きないまれなことが起きたとして,帰無仮説を捨てて対立仮説をとる。p<0.05やp<0.01という固定したα水準がよく使われるが,できれば実際の数値を記載したほうがよい。
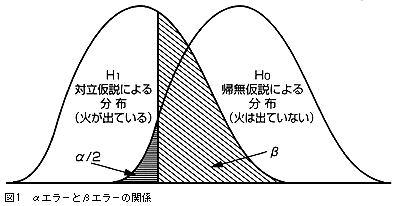
●αエラーとβエラー
求めた確率が小さいからと,偶然に起きた差を有意な差と早とちりしてしまい,帰無仮説が正しいのにそれを棄却することをαエラーと呼ぶ(「あわてんぼう」と覚える)。また,求めた確率が大きいからと,差を見逃してしまい,誤った帰無仮説を採択することをβエラーと呼ぶ(「ボンヤリ」と覚える)。その関係は表1のようになる。
これを病室の火災報知機にたとえて説明しよう。火が出ていないのに警報が鳴るのがαエラーである。火が出ているのに警報が鳴らないのがβエラーである。差があったときにその差を検出する力(火が出ると警報が鳴る)を検出力と呼び,標本数nが大きいほど強くなる。検出力=(1-β)という関係にある。一般には検出力は0.8以上が求められる。
標本の大きさが一定であれば,αとβをともに小さくすることはできない。とすると,有意差検定ではαを0.05またはそれ以下に固定しているので,βを小さく(検出力を大きく)するためにはnを大きくすることになる(図1)。
●両側検定か片側検定か
検定の仕方には,棄却域を両側に設ける両側検定と,片側だけに設ける片側検定とがある。両側検定では帰無仮説(H0)はμ=μ0で,対立仮説(H1)はμ≠μ0となる。しかし,片側検定は治療群のほうがコントロール群よりよいという前提で行なわれるので,帰無仮説H0はμ=μ0であるが,対立仮説H1はμ>μ0である。帰無仮説H0が正しいときには,両側と片側とに差はないが,棄却する際にはその棄却域が異なり,片側検定のほうが基準が甘くなる。片側検定を用いるためには,治療群のほうがコントロール群よりよいということが完全に保証されていなければならない。医学の研究では,治療群の方がコントロール群よりよいという保証はないので,治療群の有効性をいうためには両側検定が必要である。
参考までに述べると,95%信頼区間はp値が0.05の水準で受け入れられる帰無仮説の範囲を示してくれる。
●t検定
標本数が小さいと,どうしても正規分布しない。母集団の分散もわからないことが多い。そこで標本数が小さい2群間比較をするときにはt検定を用いることになる。t分布は標本数が少ないときの分布を示したものであり,標本が大きくなればt分布は正規(Z)分布に近似する。最近では,コンピュータ統計ソフトに両群のnA,nB,平均値(xA,xB),標準偏差(sA,sB)を入力すると簡単に結果を得ることができる。
事例では2群の差:4.00,SE:2.00,自由度48でt=2.000,p=0.051という結果が得られた(表2)。
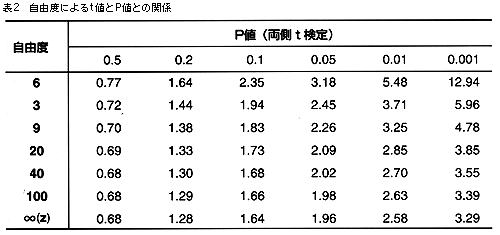
t値からp値を求めるには以下のようにする。t値は標本サイズによって異なるので,標本がn人のときには自由度(n-1)のところをみる。自由度とは「自由に動ける変数」という意味で,n人の平均値がわかっているときには,(n-1)人のデータは自由に決められるが残りの1人は自動的に決まってしまうことを意味する。
自由度が30を越えるとt値はZ値に近似するが,それ以下で統計的な有意を言うためにはZ値より大きなt値が要求される。例えば両側検定でα=0.05に当たるのは,標本数を無限とするZ値では1.96と一定であるが,25人の標本数ではt値=2.06(自由度24),5人の標本数ではt値=2.78(自由度4)になる。
これを計算で求めると,以下のようになる。スチューデントのt統計量は
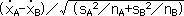
に近似する1)。
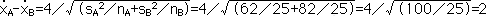
となり,t=2が得られる。
事例では,t分布表で(nA-1)+(nB-1)=48の自由度,t=2.0をさがすと,一番近い値はα=0.05で2.011であることがわかる。α=0.1のt値が1.677なので比例式を作って解くとp=0.052となる。αエラーを0.05とすると,事例の場合は偶然の範囲内ということになる。
●事例2
血糖降下剤の効果を評価するため,8人の志願者を募った。基準食をとってもらい,内服前の空腹時血糖値(FPG)と,1錠3回内服した翌朝のFPGを比較検討した。データを表3に示す1)。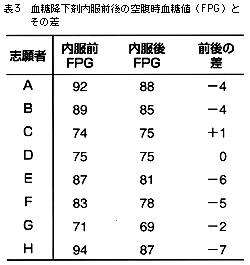
●1標本(ペア)t検定
t検定は2群が独立していることを条件にしているので,同じ人のデータをペアで比較する時には用いることができない。その際には1標本t検定を用いる。1標本t検定とt検定の違いは,分子は平均値差で同じであるが,分母が異なることである。t検定は生データの標準誤差を,1標本t検定は差の標準誤差を用いる。そのため1標本t検定は分母が小さくなる。自由度は2n-2からn-1と減少するが,分母が小さい影響のほうが強いので有意差が出やすい。
事例2では,1標本t検定を用いて,差の平均を-3.38,差の標準偏差を2.83で計算すると,
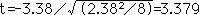
となる。自由度7(8-1=7)のt分布表をみるとP=0.012であり,FPGは内服前後で差があることがわかる。
ここで誤ってt検定を用いると,差ではなく値の標準偏差11.0で計算されるため,
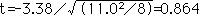
となり,自由度14(2×8-2=14)のt分布表をみるとP=0.403なので,有意差はないと間違ってしまいかねない。
●ここまでわかるとどの程度論文が読めるか?
t検定に精通していればNew England Journal of Medicineの論文の67%は読めることがわかっている2)。●まとめ
■帰無仮説には治療群のほうがコントロール群よりよいという仮定は含まれていないので,治療群の有効性を言うためには両側検定が必要である。■標本の大きさが一定であれば,αとβを 共に小さくすることはできない。有意差 を見逃さないためには,nを大きくして βを小さくする必要がある。
■標本の分散がわからない2群間比較をす るときにはt検定を用いる。
■同じ人のデータをペアで比べる場合には 1標本t検定を用いる。
参考文献
1)Feinstein AR: Stochastic Contrasts, In Clinical Epidemiology The Architecture of Clinical Research, Philadelphia, Saunders, 130-169, 1985.
2)Emerson JD, Colditz GA: Use of statistical analysis in the New England Journal of Medicine, In Bailar III JC, Mosteller F, ed.,Medical Uses of Statistics, 2nd ed., Boston, NEJM Books, 45-57, 1992.