
目的別量的研究ガイド(3)予測したい(加藤憲司)
連載
2015.01.26
量的研究エッセンシャル
「量的な看護研究ってなんとなく好きになれない」,「必要だとわかっているけれど,どう勉強したらいいの?」という方のために,本連載では量的研究を学ぶためのエッセンス(本質・真髄)をわかりやすく解説します。
■第13回:目的別量的研究ガイド (3)予測したい
加藤 憲司(神戸市看護大学看護学部 准教授)
(3105号よりつづく)
この原稿を執筆中の2014年12月14日,衆議院議員総選挙が行われました。選挙期間中,新聞などで「与党,○○議席を超す勢い」といった記事を目にした読者も少なくないでしょう。結果は皆さんご承知のように,だいたい新聞の予測通りでした。いったい誰がどんなふうに予測しているんだろう,と思ってしまいますね。
臨床場面においても,予測が求められることが多くあります。「この患者さんの予後はどうなるだろうか」「この治療法の効果はどの程度だろうか」などなど。そこで今回は,予測にまつわる量的研究のポイントを取り上げてみます。
予測には不確実性が含まれる
まず押さえておきたいのは,いかなる予測も不確実性を含んでいるということです。不確実性を含まない予測というものは存在しません。このことは第6回(第3081号)に地震の例えを用いて触れましたが,大事なことなのであらためて述べます。
例えば,「明日の天気は雨が降るか,または降らないでしょう」という“予報(?)”があったとします。この予報が当たる確率は100%ですね。だって,雨は降るか降らないかどちらかしかありませんから。こんな“予報”があっても,実生活に何の役にも立ちません。あるいは,「明日は晴れるでしょう」と毎日毎日言い続ける“予報(?)”があったとすれば,たぶん結構高い的中率になるだろうということも容易に想像できます。何だか天気予報の悪口を書いているように見えますが,実は天気予報というのは,予測がうまく機能している数少ない分野だそうです1)。それはともかく,予測の良しあしというのは,単に的中率だけを見ていてはわからないと言えそうです。
冒頭で触れた今回の選挙の予測に関して,某公共放送局では「○○~○○議席」というふうに幅を持たせていました。ズバリの数字を出していた他のTV局と比べてちょっとずるい気もしますが,予測というものに不確実性が付きまとう以上,本来はこのように幅を持たせて予測するのが正しい態度だと言えます。本連載では,「世界を確率的にとらえる」ことを推奨してきました(例えば第8回・第3089号)。それに従えば,未来の予測が1つの数字だけで示されている場合(つまり点推定)には,ちょっと怪しむぐらいの態度がちょうどよいと言えるかもしれません。
モデルは地図に似ている
話を天気予報に戻します。現代の天気予報は,「気象モデル」に数値データを入力してコンピューターで計算し,その出力を基に予報官が経験を駆使して導くのだそうです1)。ここで言う「モデル」とは,第8回で述べた統計モデルのことだと考えてよいでしょう。そこであらためて,予測におけるモデルの意義と役割について考えてみたいと思います。
予測のための統計モデルを構築することは,地図を描くことに似ています1)。役に立つ地図であるためには,河川や鉄道,幹線道路や主な建造物など,重要な情報が十分に盛り込まれていなければならないのはもちろんです。でも,地図が細かすぎると逆にわかりづらくなり,かえって道に迷う可能性があるのではないでしょうか。モデルもこれと同じです。モデルには必要な情報が含まれていなくてはなりませんが,情報は多ければ多いほどよいというわけではありません。
一つ具体例を挙げます。図を見てください。これは血液透析患者の自己管理に影響を与える要因を検討する目的で作られたモデルです2)。「影響」というのは時間的前後関係を想定した言葉ですから,「予測」と言い換えてもよいでしょう。ここでは患者の自己管理を「セルフ・エフィカシー」「ソーシャル・サポート」「食行動」の3つの量的変数で予測しようとしています(「食行動」は実際には3つの下位尺度から成ります)。また,自己管理の指標としては,調査後1週間の「体重増加率」(これも量的変数)を用いています。
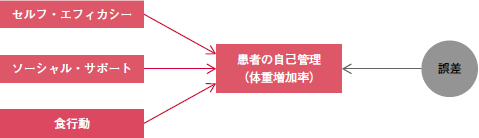 |
| 図 血液透析患者の自己管理に影響を及ぼす要因モデル(文献2を参考に筆者が作成) |
さて,このモデルの予測力がどれくらいあるのかを知るには,どうしたらよいでしょうか。それは,「体重増加率」のデータが持つ情報量のうち,図の左側の3変数(つまり,予測に用いる項目)で説明できる情報量の占める割合によって示されます。「情報量」などと言うと難しく聞こえるかもしれませんが,データの散らばり具合の程度のことだと思ってください。データが散らばるということは,それだけ情報量が多いということを意味します。そして,これらの3つの変数で説明し切れない残りの情報は,図の右側の「誤差」でまとめて表されています。
先ほどの地図との対比の話に戻ると,このモデルが役に立つモデルであるためには,これらの3つの変数が重要なものでなければなりません。重要かどうかは,統計分析(重回帰分析)をして有意であるかどうかを調べてみればわかります。モデルの予測力も同様に調べられます(決定係数)。今,ここで言いたいのは,もしモデルの変数の数をどんどん増やしたらどうなるかについてです。変数の数を増やせば,予測力はアップします。でもそれと引き換えに,地図としての見やすさ,理解しやすさを犠牲にするのは得策ではありません。しかも,さほど重要ではない変数をモデルに加えても,それによってアップする予測力はわずかにすぎません。
モデルはシンプルなほど良い
全てのモデルは,世界をやむを得ず単純化したものです1)。どこまで単純化するかは,あなたが取り組んでいる問いがどのようなものであるか,そしてどの程度正確な答えを求めているかによります。モデルの良さを表現する言葉に,「倹約性」があります。平たく言えば「けち」ということです。なるべく少ない費用(すなわち変数の数)で多くの利益(すなわち予測力)を上げることが,良いモデルの目標です。
今回の前半で述べたように,「100%当たる予測」つまり「誤差=0のモデル」というのは意味がありません。その一方で,「予測力=0のモデル」もやはり意味がありません。モデルによる予測というのは,「誤差=0」と「予測力=0」の中間にあって,できるだけ“コストパフォーマンス”よく世界を切り取ることだと言えるでしょう。なお,今回述べた内容は予測を目的とする場合以外のモデルについても当てはまるものですので,参考にしてみてください。
今回のエッセンス●予測には不確実性が含まれる●モデルは地図に似ている ●モデルはシンプルなほど良い |
(つづく)
参考文献
1)ネイト・シルバー,川添節子訳,西内啓監修.シグナル&ノイズ――天才データアナリストの「予測学」.日経BP社;2013.
2)高岸弘美.血液透析患者の自己管理に影響を及ぼす要因とそれらの関連性に関する研究――セルフ・エフィカシー,ソーシャル・サポート,食行動に焦点をあてて.山梨県立大学看護学部紀要.2008;10:13-26.
いま話題の記事
-
人工呼吸器の使いかた(2) 初期設定と人工呼吸器モード(大野博司)
連載 2010.11.08
-
忙しい研修医のためのAIツールを活用したタイパ・コスパ重視の文献検索・管理法
寄稿 2023.09.11
-
連載 2010.09.06
-
事例で学ぶくすりの落とし穴
[第7回] 薬物血中濃度モニタリングのタイミング連載 2021.01.25
-
寄稿 2016.03.07
最新の記事
-
医学界新聞プラス
[第3回]人工骨頭術後ステム周囲骨折
『クリニカル・クエスチョンで考える外傷整形外科ケーススタディ』より連載 2024.04.19
-
医学界新聞プラス
[第2回]心理社会的プログラムを分類してみましょう
『心理社会的プログラムガイドブック』より連載 2024.04.19
-
医学界新聞プラス
[第1回]心理社会的プログラムと精神障害リハビリテーションはどこが違うのでしょうか
『心理社会的プログラムガイドブック』より連載 2024.04.12
-
医学界新聞プラス
[第2回]小児Monteggia骨折
『クリニカル・クエスチョンで考える外傷整形外科ケーススタディ』より連載 2024.04.12
-
医学界新聞プラス
[第5回]事例とエコー画像から病態を考えてみよう「腹部」
『フィジカルアセスメントに活かす 看護のためのはじめてのエコー』より連載 2024.04.12
開く
医学書院IDの登録設定により、
更新通知をメールで受け取れます。
医学界新聞公式SNS
シェアする



URLをコピーしました