
「医療ビッグデータ時代」の幕開け(中山健夫)
寄稿
2015.01.05
「医療ビッグデータ時代」の幕開け
中山 健夫(京都大学大学院医学研究科社会健康医学系専攻健康情報学分野教授)=執筆
ここ数年,さまざまな領域で「ビッグデータ」活用の動きが活発化している。ビッグデータとは「通常のデータベース管理ツールなどで取り扱うことが困難なほど巨大なデータの集まりであり,構造化データおよび非構造化データを含む」と定義され,その特徴として,Volume(量),Velocity(迅速性),Variety(多様性),そしてVeracity(正確性)を加えた“4V”が強調されている(図1)。
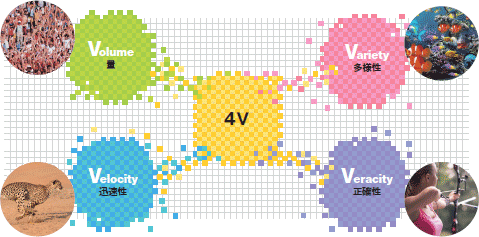 |
| 図1 ビッグデータの“4V” |
| 迅速性とは,データの生成速度の速さや更新頻度の多さ,正確性とは測定の妥当性,対象の再現性などを指す。 |
2010年に全世界で生成・複製されたデジタルデータ量は1200エクサバイト(1エクサバイト=10億ギガバイト),それが15年には8500エクサバイト,20年には4万エクサバイト(40ゼタバイト)に達する見込みだ(図2)。ゼタバイトの1000倍,「ヨタバイト」の世界も,予想より早く訪れるかもしれない。この急速なデータ量の増大が「ビッグデータ」という言葉を生みだしたと言える。
 |
| 図2 デジタルデータ量は「ゼタ」の時代へ |
医療・医学領域でも,ビッグデータへの関心は年々高まっている(図3)。ただ,この領域において現段階で整備・活用が進んでいるのは,構造化済みのいわば「大規模データ」である。この大規模データこそが,無限に広がっているであろうビッグデータの世界への現実的な入口と言えよう。
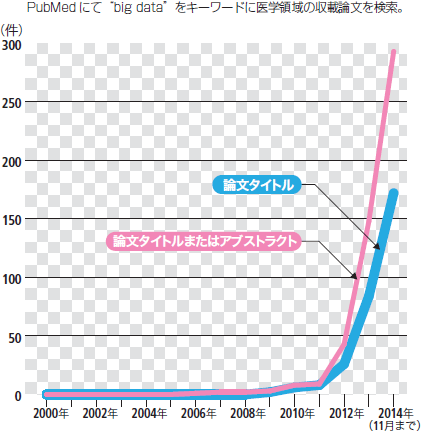 |
| 図3 「ビッグデータ」関連医学論文の動向 |
| PubMedにて“big data”をキーワードに医学領域の収載論文を検索。 |
本稿では,医療・医学のビッグデータの壮大な世界への導入として,国内の大規模データの最近の動向を,「医療(ヘルスケア)」と「生命科学(ライフサイエンス)」という2つの大きな軸から概観し,今後の展望を述べたい。
ヘルスケア領域の大規模データ:業務データと症例レジストリ
ヘルスケア領域におけるデータベース(以下,DB)として格段に情報量が多いのは,通常の診療活動から自動集積される“業務データ(administrative data)”,DPCデータとレセプトデータである。DPCデータは,DPC(Diagnosis Procedure Combination;診断群分類)に基づいた患者の臨床情報と,なされた診療行為の電子データセットを指す。03年にわずか82の特定機能病院で導入されたDPCに基づく支払い制度は,14年度には約1860の病院・約53万床(全一般病床の約59%)が参加または参加準備中になるまでに普及。年間約878万件(11年度)のDPCデータが蓄積されている。
DPCが急性期病院の入院医療のみを対象にする一方,慢性期や入院外まで,ほぼ全ての医療機関と調剤薬局をカバーするのが,レセプト(診療報酬明細)のデータである(図4)。かつては年間14億枚もの紙出力で,医療機関から市町村・健康保険組合等の保険者へと請求されていたレセプトデータだが,06年に完全オンライン請求が構想され,11年には原則義務化。現在,件数ベースで90%以上の電子化が達成されている。それを受けて,08年に施行された「高齢者の医療の確保に関する法律」に基づき,レセプトおよび特定健診のデータベース(National Data Base;NDB)構築が開始。09年から14年7月診療分までに約83億4800万件が蓄積され,今後も約18億件/年の増加が見込まれる。
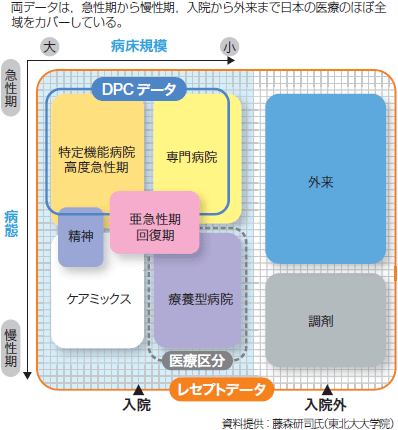 |
| 図4 DPCデータとレセプトデータのカバー範囲 |
| 両データは,急性期から慢性期,入院から外来まで日本の医療のほぼ全域をカバーしている。 |
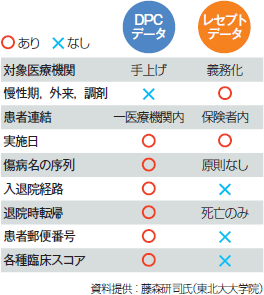
DPCデータとレセプトデータにはそれぞれ一長一短がある。例えばDPCデータは統一性が高く非常に詳細で緻密だが,一医療機関内でしか患者情報が把握できない。一方,レセプトデータは傷病名の正確性に欠けるが,同一保険者内ならば患者情報を連結できる。ただし郵便番号がないため,患者所在地の把握が困難な場合がある(表)。とはいえ,両データを活用すれば日本の医療の現状をほぼ把握可能であり,地域への医療資源の適正配置の検討から,医療的介入の有効性,個々の診療とエビデンスとのギャップ評価にまで活用できる。
| 表 DPC データとレセプトデータの違い |
 |
DPCデータは一般公開されていないのに対し,NDBは行政や地方自治体による利用のほか,研究目的での利用が11年から試験的に認められてきた。例えば現在,医薬品医療機器総合機構(PMDA)が1000万人規模の「医療情報データベース」を整備し,医薬品安全対策の薬剤疫学的基盤を作ろうとしている。そこに研究利用が許可されたレセプトデータも組み込まれ,14年10月より運用中の医薬品リスク管理計画(Risk Management Plan;RMP)にも活用される予定だ。なお,14年にはNDBにアクセスできるオンサイトセンターが東京大学と京都大学に設置され,今後のさらなる研究活用拡大への道筋も整備されつつある。
また,臨床家が独自にデータを登録して構築する「症例レジストリ」も各領域で発展している。その筆頭が,00年に心臓血管外科領域から始まり,10年に全外科,本年から脳神経外科領域も合流するNational Clinical Database(NCD)だろう。NCDへの症例登録が,専門医制度指定修練施設の指定,または専門医資格取得に必須のため,14年度までに全国4000施設以上から約414万症例が登録済。外科手術の質向上に多大な貢献をしているほか,多様な臨床研究を推進する基盤となっている。
ライフサイエンス領域の大規模データ:ゲノムDB
一方,「生命科学(ライフサイエンス)」領域のDBの発展も著しい。DNAの二重らせん構造が発見された1953年から50年目にあたる2003年,約30億塩基対という膨大なヒトゲノムの解読が完了。研究者の総力を挙げた取り組みは,生命科学・生物医学を新たなステージに押し上げた。
解読されたゲノム情報の“意味”を明らかにするため,00年代前半からは人間集団を対象としたゲノム疫学(分子疫学)への関心が急速に高まった。海外では英国がバイオバンク・プロジェクトに取り組み,50万人のゲノム情報を蓄積,大規模な疫学研究を推進している。国内でもがんや生活習慣病の予防対策を目的に,国立がん研究センターなどによるJPHC・JPHC-NEXT,愛知県がんセンター・名古屋大学などによるJ-MICC,東北大学などによる東北メディカル・メガバンク機構がそれぞれ,数万から10万人規模のゲノムコホート研究として運営されている。また,地域密着の取り組みとして,滋賀県長浜市にて市と京都大学が連携し,1万人規模のコホート研究が実施されている(図5)。
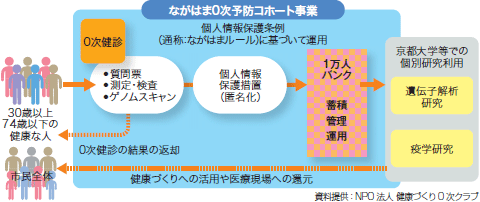 |
| 図5 ながはま0次予防コホート事業の概要 |
| 質問票による環境・生活習慣情報742項目,生理学・血液学・生化学測定値145項目に加え,3713検体のゲノムスキャンを実施し,その後も定期的に健康情報を蓄積する。数十年単位でデータを集積することで,環境や生活習慣,遺伝が疾病の発症メカニズムにおよぼす影響を解明する計画だ。条例(通称:ながはまルール)の制定や,市と京大とで二重の倫理審査体制をとるなどして,ゲノムを含む個人情報の蓄積・活用への配慮も厳格に行われている。 今後は,MRIの脳画像やウェアラブルデバイスによるライフデータの記録なども予定されており,発症阻止・遅延などの「先制医療」の実現が期待される。 |
なお国内のゲノム情報は「散在するデータベースを,まとめて,使い易く」のスローガンのもと,科学技術振興機構のバイオサイエンスデータベースセンターにて統合化が進んでいる。
*
まとめると,医療・医学における主要な大規模DBとその活用方法は,現時点で以下4つに大別されよう。
(1)地域の医療資源配置・医療計画策定(主にDPCデータ,レセプト)
(2)医療の質向上,臨床研究(主に症例レジストリ)
(3)医薬品の安全性評価(主にレセプト,電子カルテ)
(4)疾患の原因解明,予防(ライフサイエンス領域:ゲノムDB)
医療・医学におけるビッグデータは,多様で膨大な個人データの集積に加え,ヒトの微視的で精緻な生命活動,健康状態,医療や健診受診などの人為的な事象,さらには社会的な行動など,異なる次元の現象の精密な分析・測定によるデータ化の両面で加速的に拡大している。
レセプトDBの活用事例:重複受診の実態解明
大規模DBの活用例として,同一疾病で複数の医療機関を受診する「重複受診」の実態解明の試みを紹介したい。
厚生労働省の受療行動調査などで,同一疾病で複数の医療機関に受診している者の割合は示されているが(5.8%,2008年),これは自記式調査であり,その実態を把握することには限界があった。客観的・網羅的な実態把握ができれば,データに基づいて,在るべき医療の姿を議論できる。
そこで,複数の健康保険組合のレセプトデータ約100万人から抽出した,12年12月の外来患者の全処方データを分析。ATC分類(解剖治療化学分類法)の第2レベル(治療法メイン)で同分類の医薬品が処方された患者と医療機関の数を明らかにした。すると,例えば「咳と感冒用製剤」は,同月内に0-19歳の約11%が複数の医療機関で処方を受けていた(図6)。全身用抗菌薬,全身用抗ヒスタミン薬も約9%が複数の医療機関を受診し,同種の薬を処方されていたことがわかった。
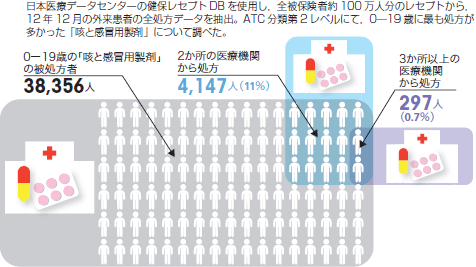 |
| 図6 レセプトデータからわかる,「重複受診」の実態 |
| 日本医療データセンターの健保レセプトDBを使用し,全被保険者約100万人分のレセプトから,12年12月の外来患者の全処方データを抽出。ATC分類第2レベルにて,0-19歳に最も処方が多かった「咳と感冒用製剤」について調べた。 |
DPCデータや臨床系学会の症例レジストリと異なり,レセプトは被保険者が受診した医療機関を網羅的に把握できるため,年齢,医薬品の種類を考慮した重複受診の実態解明に最も適したデータと言える。
壮大で精密な「リアルワールドデータ」誕生に向けて
医療・医学の大規模データベースは,それぞれが独立に構築,利用されている。現在,それらを相互に関連付けて,個人の特性や受けた医療行為とその後の健康状態の関係を明らかにし,個々の診療の改善から医療政策にまで生かせるエビデンスを継続的に生み出す仕組みの議論が始まっている。そこでは,出生に始まり,小児,児童,成人,壮年,老年を経て死に至る人間の一生を通じたデータの連携(「ライフコースデータ」)が大きな意味を持つ(図7)。
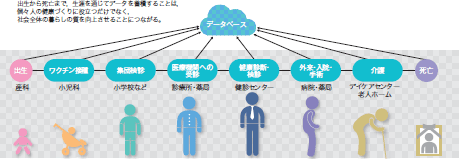 |
| 図7 「ライフコースデータ」の蓄積 |
| 出生から死亡まで,生涯を通じてデータを蓄積することは,個々人の健康づくりに役立つだけでなく,社会全体の暮らしの質を向上させることにつながる。 |
わが国はこれらの多様なデータが法的な基盤の上に蓄積されている稀有な国と言え,全国民のライフコースデータが経時的に蓄積されれば,従来見えなかった大きなトレンドが明らかになるだけでなく,個々の多様さも全て包含された,壮大で精密な「リアルワールドデータ」が誕生するだろう。
16年からは「社会保障・税番号制度(マイナンバー)」の利用が始まるが,健康や医療の情報は今のところ対象外である。しかし,国民一人ひとりが生涯を通じて可能な限りの健康を実現し,適切な医療の提供・利用が継続できる社会は,多くの人々の共通の願いであろう。また,その実現に向け,個人レベルでさまざまなデータが連結され,詳細な解析が可能となる情報基盤の整備は,国と国民が向き合うべき大きな社会的課題である。購買行動や移動情報など,多様な生活情報のデータと健康・医療データとが関連付けられれば,新たな社会的イノベーションの視点を提示できる可能性も生まれよう。
このような“次の段階の”ビッグデータは,私たちが従来手にしてきたデータとは質・量ともまったく次元の異なる意味と価値を持つものになる。その構築と活用に際しては,私たちは国民として,そして医療者として,“夢”とこれまで以上の“思慮深さ”を持って臨まねばならない。
「ヒューマン・データサイエンティスト」への期待
ビッグデータ時代の幕開けとともに,膨大なデータを扱える「データサイエンティスト」への需要も高まっている。“人間を扱う”医療・医学領域のデータを,その可能性とリスクの両面を理解し,最大限に活用できるのはどのような人材だろうか。
ビジネス領域であれば,データから導かれた相関関係を元に迅速に商業的な利益を生み出せれば“成功”であり,失敗しても“次”があることが多い。一方医療においては,もしデータの解釈を誤って拙速な介入を行えば,人の生命をリスクにさらす。安易に“次へ”とは決して言えないし,どれほど膨大なデータでも,表面的な相関関係のみで介入の有効性や安全性を判断すべきではないだろう。これらを踏まえ適切な意思決定につなげるには,医学的知識,因果関係を慎重に見極める疫学的知識,情報を適切な人と場に提供する能力が欠かせない。こうした能力を持つ人材は,すでに活躍中の疫学者,生物統計家,バイオインフォマティシャンらも包含し,いわば「ヒューマン・データサイエンティスト」と呼べるだろう。
リアルワールドに向き合い,ミクロからマクロまで多様で膨大な人間のデータを人間と社会のために役立てる「ヒューマン・データサイエンティスト」はどのような新しい価値を創り出していけるのだろうか。その大いなる可能性の探求が,2015年の意義あるチャレンジとなることを願い,新年の序としたい。
いま話題の記事
-
忙しい研修医のためのAIツールを活用したタイパ・コスパ重視の文献検索・管理法
寄稿 2023.09.11
-
人工呼吸器の使いかた(2) 初期設定と人工呼吸器モード(大野博司)
連載 2010.11.08
-
連載 2010.09.06
-
事例で学ぶくすりの落とし穴
[第7回] 薬物血中濃度モニタリングのタイミング連載 2021.01.25
-
寄稿 2016.03.07
最新の記事
-
医学界新聞プラス
[第2回]心理社会的プログラムを分類してみましょう
『心理社会的プログラムガイドブック』より連載 2024.04.19
-
医学界新聞プラス
[第3回]人工骨頭術後ステム周囲骨折
『クリニカル・クエスチョンで考える外傷整形外科ケーススタディ』より連載 2024.04.19
-
医学界新聞プラス
[第2回]小児Monteggia骨折
『クリニカル・クエスチョンで考える外傷整形外科ケーススタディ』より連載 2024.04.12
-
医学界新聞プラス
[第5回]事例とエコー画像から病態を考えてみよう「腹部」
『フィジカルアセスメントに活かす 看護のためのはじめてのエコー』より連載 2024.04.12
-
医学界新聞プラス
[第3回]学会でのコミュニケーションを通して自分を売り込む!
『レジデントのためのビジネススキル・マナー――医師として成功の一歩を踏み出す仕事術55』より連載 2024.04.12
開く
医学書院IDの登録設定により、
更新通知をメールで受け取れます。
医学界新聞公式SNS
シェアする



URLをコピーしました