
回帰分析モデルの選び方(新谷歩)
連載
2011.06.20
医療統計学講座
【Lesson2】
回帰分析モデルの選び方
新谷歩(米国ヴァンダービルト大学准教授・医療統計学)
(2927号よりつづく)
臨床研究を行う際,あるいは論文等を読む際,統計学の知識を持つことは必須です。
本連載では,統計学が敬遠される一因となっている数式をなるべく使わない形で,論文などに多用される統計,医学研究者が陥りがちなポイントとそれに対する考え方について紹介し,臨床研究分野のリテラシーの向上をめざします。
飲酒と肺がんの関連を調べるため,肺がん患者と健常者の飲酒率を比較したところ,肺がん患者の飲酒率は健常者に比べ統計的な有意差をもって高いことが分かりました。では,肺がんと飲酒の間に関連性があると言えるでしょうか? 答えは明らかにノーです。通常飲酒者の間では喫煙率が高く,飲酒が肺がんに関連しているのか,喫煙が関連しているのか,不明だからです。このような現象を,疫学および統計学の専門用語で「交絡」と呼びます。
交絡の意味
交絡とは,アウトカム(肺がん)に直接影響を及ぼすような研究対象外の関連因子(喫煙)が,研究対象である暴露因子(飲酒)と関連性があるときに起こります。交絡が起こると研究対象である暴露因子(飲酒)と交絡因子(喫煙)が混ざり合ってしまい,本当の暴露因子(飲酒)の効果を調べることができなくなり,この場合喫煙は交絡因子と見なされます。
マウスなどの動物を使った基礎研究とは異なり,人を対象とする臨床研究では研究環境のコントロールが難しく,この交絡をどう防ぐかで臨床研究の質が決まると言っても過言ではありません。そのため,交絡を防ぐためのさまざまな研究デザインおよび統計手法が考案されてきました。最もよく使われる研究デザインの一つであるランダム化比較試験では,コインの表が出れば「介入あり」,裏が出れば「介入なし」のように,患者が介入治療を受けるかそうでないかの割り付けを完全に無作為に行うことによって,両群間の患者の性質をそろえることができます。これにより,両群間の違いは「介入があるか,ないか」のみと限定でき,観測される違いがまさしく介入治療によるものだと判断できます。
それでは,ランダム化が可能でない臨床研究の場合はどうでしょうか。例えば,ICUにおけるせん妄と6か月後の死亡率の関連を問う研究で,ICUの入院患者をランダムに「せん妄あり,なし」に割り付けることはできません。たとえ「せん妄あり」の群で6か月後の死亡率が高く出たとしても,それは「せん妄あり」の群に高齢患者が多いことによるものなのかもしれません。
このような場合の有効な交絡防止手段となるのが回帰分析です。回帰分析を使うことにより年齢に依存する死亡率を考慮に入れ,その影響を差し引いた後せん妄と死亡率の関連を調べることができます。これを「回帰分析による交絡の補正」と呼んでいます。交絡の補正法には,例えば,研究を高齢者のみに限定する方法や,「せん妄あり,なし」のグループ間で高齢者の数をそろえるマッチング法などもあります。臨床研究などデータ数が限られている場合は回帰分析による補正が最も有効です。
この回帰分析による補正の考え方について,ぴんとこないと言われることが多いのですが,実は日常私たちがごくごく普通に使っている考え方です。私の9歳になる娘は,6歳の妹に「妹は1桁の足し算しかできない,掛け算のできる自分のほうが偉い」と得意げに言います。「6歳なんだから掛け算ができないのは当たり前でしょ,あなたも6歳のころはできなかったのよ」と言っても,どうして自分のほうが偉くないのか理解できないようです。
この場合の交絡の補正とは,年齢による算数能力の違いを考慮に入れ,それを差し引いた後,つまり9歳の娘が「自分が妹と同じ6歳のときはどうだっただろう」と算数能力を比較するということです。どうやら娘は年齢による算数能力の補正ができないようですね。
一般に,ランダム化比較試験では交絡が生じにくいため,解析もt検定やカイ2乗検定など単変量解析で済ませられますが,ランダム化のない観察研究では,回帰分析などによる交絡の補正が不可欠です。単変量解析のみでは,国際誌に研究結果を発表することはほとんど不可能です。
回帰分析モデルの選択の仕方
ではここからは,回帰分析モデルの選択方法のポイントについてお話しします。まずは,下記に挙げた3つの研究における適切なモデルを選んでください。
研究1 新規の鎮静薬を投与した50人の患者と投与しない50人の患者間で,重篤度を補正しながら入院日数を比較する。 研究2 30人の慢性腎臓病患者のBMIと炎症マーカー(CRP)の相関を,性別を考慮に入れて調べる。 研究3 ICUに入院中のせん妄の有無について,入院中毎日測定し変化を調べる。 [選択肢]線形回帰モデル,順序ロジスティック回帰,2値ロジスティック回帰,コックス比例ハザードモデル,混合効果モデル,一般化推定方程式 |
データに合った回帰分析モデルを選択する際のポイントは4つ。単変量解析の場合より少なく簡単です(表)。
| 表 回帰分析モデルを選択する際の4つのチェックポイント |
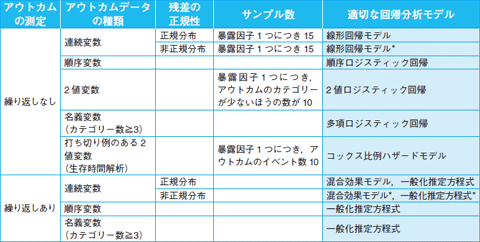 |
□ アウトカムは繰り返し測定されているか?
一般に知られているモデルは解析されるアウトカムの一つひとつがそれぞれ別の患者から集められたデータであると想定され,P値の計算が行われます。それに対し,1人の患者からデータが繰り返し2回以上測定されている場合には,別な回帰モデルを使って繰り返しを考慮に入れ,P値の計算を行います。
□ アウトカムは,連続変数,順序変数,名義変数,2値変数のいずれに分類できるか?
前回(第2927号)お伝えしたアウトカムの種類と同様,アウトカムの種類でモデルが変わります。
□ アウトカムが連続変数の場合,その分布は正規分布であるか?
アウトカムが連続変数の場合に使われる線形回帰モデルや混合効果モデルは,残差(アウトカムと回帰モデルによる予測値の差)が正規分布だと想定してP値の計算が行われるため,そうでない場合はアウトカムをログ,ルート,2乗,3乗など数学変換し,残差の分布をできる限り正規分布に近付けます。
□ サンプル数は十分か?
回帰モデルでは,複数の暴露因子とアウトカムの関連性を調べられるという利点がありますが,あまりに多くの暴露因子を入れすぎるとモデルが不安定になり,結果が狂ってしまいます。そのため,サンプル数はモデルに入れる暴露因子の数に合わせて大きくする必要があります。例えば,肺がんと飲酒喫煙の関連を調べる場合,肺がんを示すアウトカムが連続変数のときに用いられる線形回帰モデルでは,サンプル数は「暴露因子数×15」,つまり30人の被験者が必要となります。
2値のアウトカムに使われるロジスティック回帰モデルでは「あり,なし」のような2値のアウトカムの少ないほうの数が「暴露因子数×10」以上であるようにサンプルを集めます。この例では,肺がんの発症率を10%とすると,20人の被験者が「肺がんあり」となるためには最低200人が必要になります。コックス比例ハザードモデルでは,2値のアウトカムの「あり」の群の数が「暴露因子数×10」となるようサンプル数を決めます。
質問の答えは順に,研究1:アウトカムを数学変換で正規分布にした線形回帰モデル,研究2:線形回帰モデル,研究3:混合効果回帰,一般化推定方程式です。いかがでしたか?
|
(つづく)
参考文献
1)Harrell, et al. Regression Modeling Strategies. Springer-Verlag; 2001.
2)Peduzzi P, et al. A simulation study of the number of events per variable in logistic regression analysis. J Clin Epidemiol. 1996; 49(12): 1373-9.
3)Peduzzi P, et al. Importance of events per independent variable in proportional hazards regression analysis II. Accuracy and precision of regression estimates. J Clin Epidemiol. 1995; 48(12): 1503-10.
いま話題の記事
-
忙しい研修医のためのAIツールを活用したタイパ・コスパ重視の文献検索・管理法
寄稿 2023.09.11
-
人工呼吸器の使いかた(2) 初期設定と人工呼吸器モード(大野博司)
連載 2010.11.08
-
連載 2010.09.06
-
事例で学ぶくすりの落とし穴
[第7回] 薬物血中濃度モニタリングのタイミング連載 2021.01.25
-
寄稿 2016.03.07
最新の記事
-
医学界新聞プラス
[第3回]人工骨頭術後ステム周囲骨折
『クリニカル・クエスチョンで考える外傷整形外科ケーススタディ』より連載 2024.04.19
-
医学界新聞プラス
[第2回]心理社会的プログラムを分類してみましょう
『心理社会的プログラムガイドブック』より連載 2024.04.19
-
医学界新聞プラス
[第5回]事例とエコー画像から病態を考えてみよう「腹部」
『フィジカルアセスメントに活かす 看護のためのはじめてのエコー』より連載 2024.04.12
-
医学界新聞プラス
[第3回]学会でのコミュニケーションを通して自分を売り込む!
『レジデントのためのビジネススキル・マナー――医師として成功の一歩を踏み出す仕事術55』より連載 2024.04.12
-
医学界新聞プラス
[第1回]心理社会的プログラムと精神障害リハビリテーションはどこが違うのでしょうか
『心理社会的プログラムガイドブック』より連載 2024.04.12
開く
医学書院IDの登録設定により、
更新通知をメールで受け取れます。
医学界新聞公式SNS
シェアする



URLをコピーしました